郵便番号は、1つの郵便番号に1つの町域が割り当てられいる、というふうにはなっていない。
1つの郵便番号に複数の町域が登録されている地域は、複数存在する。
下記記事にもその注意点が記載されている。
https://qiita.com/_takwat/items/3a121656425fac7bb820
実際に、452-0961で選択クエリを実行すると、66件の住所が出てくる。
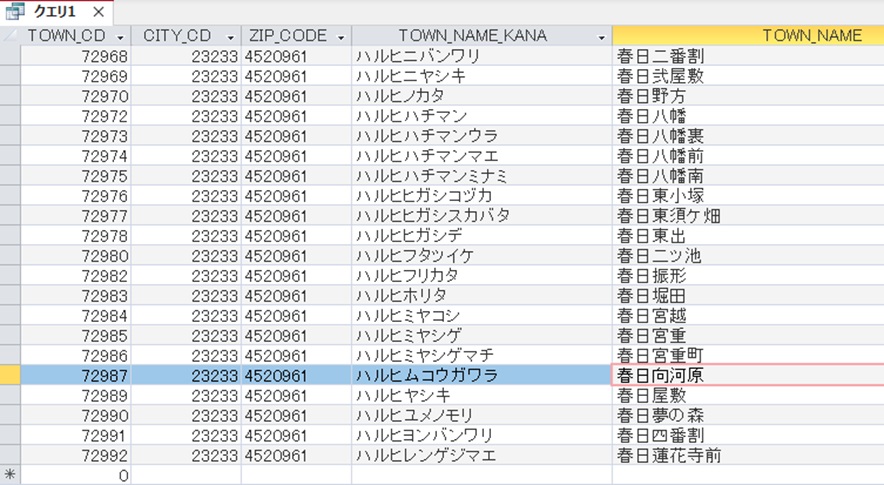
住所から郵便番号を特定するのは難しい。
郵便番号で住所を自動登録するときにも、注意が必要。
この例だと、「春日」までは共通しているので、1つのZIPCODEで複数のレコードが選択されたら、
共通する最初の文字までしか住所を入れない、などの処置が必要。
12万件データがあるので、どんなときでも問題なく動くシステムを作るのは難しいと頭に入れておくこと。
重複するデータを調べる方法を試す。
T03_CityテーブルからZIP_CODEだけを表示。全124386レコードが表示される。
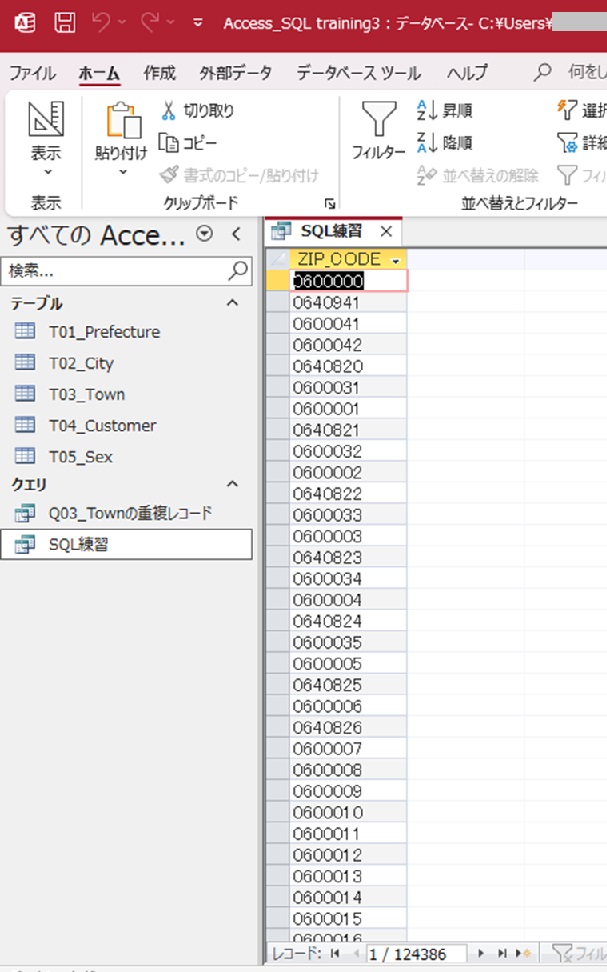
GROUP BYでグループ化して実行する。
SELECT ZIP_CODE FROM T03_Town GROUP BY ZIP_CODE;
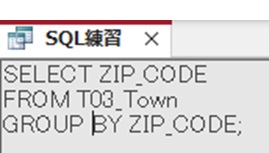
グループ化した場合は120553レコード。
全124386レコード - 重複しない120553レコード = 重複したレコードは3833件。
重複するZIP_CODEで、それぞれ何件の重複があるか確認する。
SELECT ZIP_CODE,Count(ZIP_CODE) AS CNT FROM T03_Town GROUP BY ZIP_CODE;
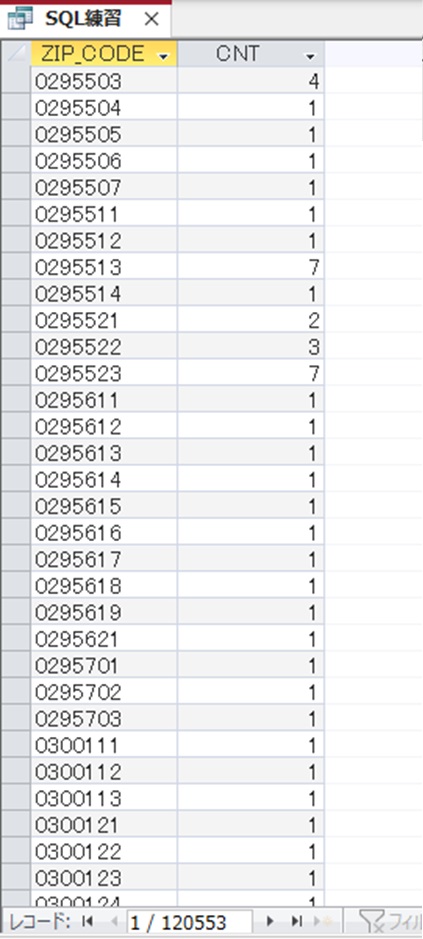
上記で、2件以上の重複があるZIP_CODEだけを表示する。
SELECT ZIP_CODE,Count(ZIP_CODE) AS CNT FROM T03_Town GROUP BY ZIP_CODE
HAVING (cOUNT(ZIP_CODE)>=2);
1342個のZIP_CODEで重複があることが分かる。
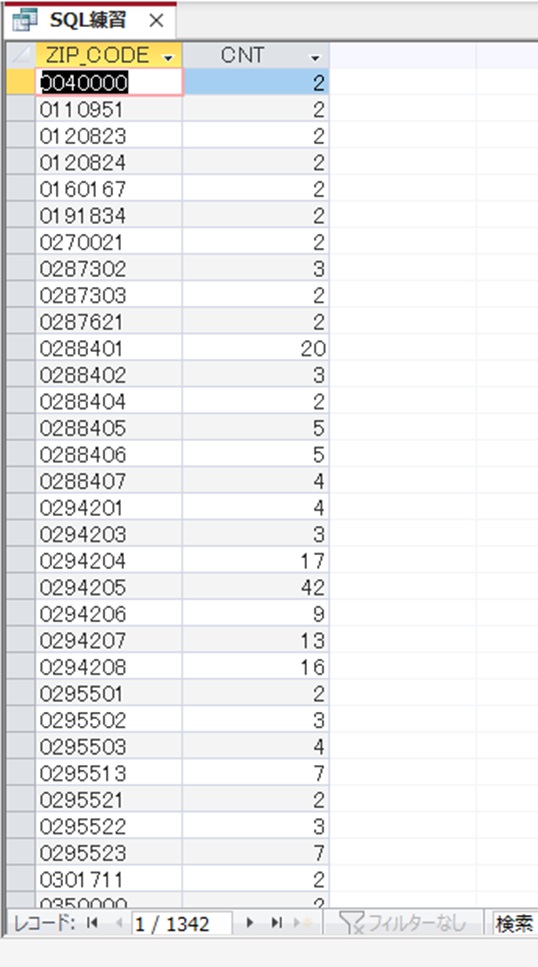
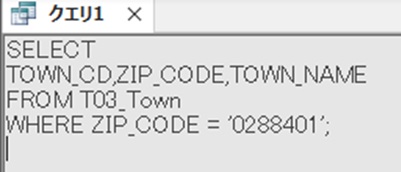
実際に、20件の重複がある、「0288401」を見てみる。
SELECT TOWN_CD,ZIP_CODE,TOWN_NAME FROM T0_Town WHERE ZIP_CODE = ‘0288401’;
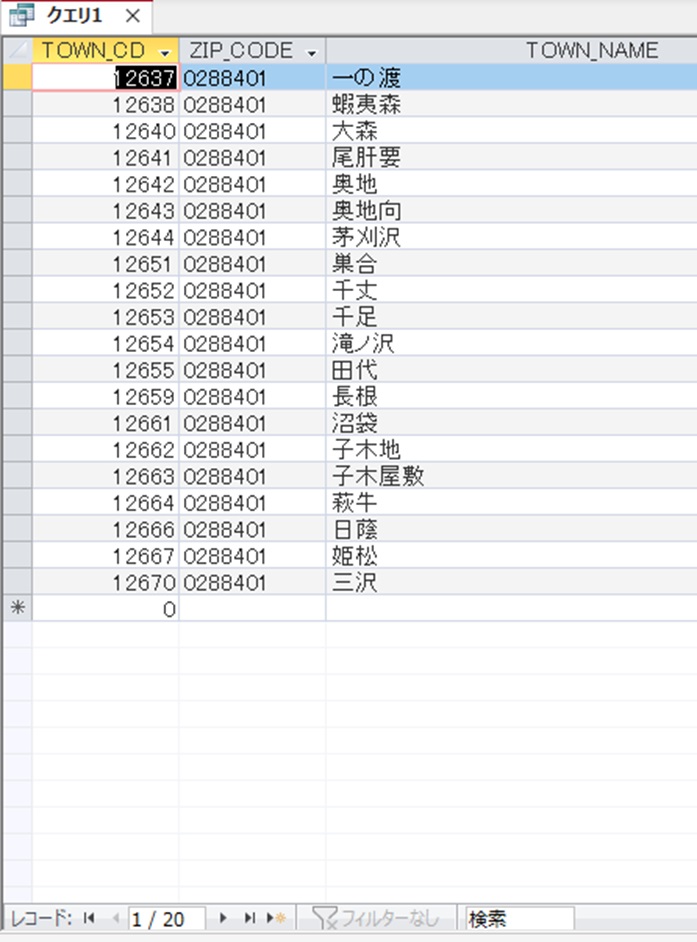
ZIP_CODEは重複しているが、TOWN_CDがあるので、TOWN_CDで識別ができる。
ちなみにTOWN_CDは、郵便番号データから、都道府県名、市区町村名、町域名の3つのテーブルに分割したときに、
市区町村名データ(T02_City)にオートナンバー型で付与した番号。(ZIPCODE.accdb を参照)
現状、自分で追番を付ける以外は、重複しないデータを作成するのは難しそう。
